Welcome to my first post on the Google Mashup Editor. In this article we'll create a tool for entering and storing data using Google's new mashup editor tool. Depending on available time, the evolution of Google Mashup Editor and the availability of alternative tools, I might improve on the basic data management application in later articles.
Scrum project management
The application we'll be creating is a Scrum project management tool. If you don't know Scrum yet, it's an agile project management framework. Please do yourself a huge favor and read
this 90 page story about Scrum (
pdf). It's a good and fun read and has already won over many organizations to at least give Scrum a try.
My reasons for wanting to create this type of application are many. One of them is that there seems to be no tool that satisfies my needs with the right price tag. XPlanner is good, but very basic. Mingle looks nice, but is too expensive and a real resource hog. ExtremePlanner also looks nice, but again: it seems a bit expensive for my taste. But one other reason is probably more important than the price issue: building this data model seems do-able and gives me a chance to get to know Google Mashup Editor a bit more.
Google Mashup Editor
Mashup tools seem to be a dime a dozen these days. These tools try to take programming to the masses, allowing everyone to create complex web applications based on existing data or logic.
Yahoo was the first big player in this field, with their
Yahoo Pipes. They're aiming for a
visual programming environment where the user manipulates blocks rather than writing code. Microsoft followed suit with
Popfly, an even richer mashup creation environment combined with what seems to be the next generation of their MSN Spaces platform.
Google was the last entrant into this field (if I recall correctly) and the first glances at their entry into the field left me rather disappointed. No drag-and-drop programming, no cool default widgets, just a pretty basic text editor and some basic tags.
But if you look below the surface you can see that Google Mashup Editor (GME) is actually quite different from the other two. Where Yahoo and Microsoft just seem to focus on allowing you to read and combine data from various sources, Google also allows you to create new applications from scratch. In that respect GME is more of an application creation (and hosting) platform than a mashup editor.
Much of these additional possibilities seem so originate from Google's adoption of the
Atom Publishing Protocol, exposed through the
Google Data (GData) APIs. This API is what makes GME not only a mashup editor, but also a valid tool for creating completely standalone applications. These applications are then hosted on Google's servers, using Google's servers for data storage, using the GME to create and update the applications. Some people might not like to put so much in the hands of Google. But it will certainly lower the bar for creating scalable web 2.0 applications.
That's enough of the background talk. Let's get to work on the application.
Initial data model
We'll start by defining the basic entities and relations in our application. We'll probably expand on these later, but we can get pretty far with just the following.
A project is something on which a team works in sprints to create a product or a release of a product. This is all intentionally very vague, as our application doesn't need to know the details of the projects it manages.
A project has a product owner and a scrum master. Aside from that there are other team members, but we'll leave them out of the equation for now.
A sprint is a time period during which the team implements certain stories. A sprint has a start date and end date and a description of the general goal of the sprint.
A story is a piece of functionality that the team creates. It has a name, a description of how to demonstrate it and an estimate of the effort it will take to create the functionality. Stories can be either user-focused or technical in nature.
All stories combined are called the product backlog. Stories from the product backlog are planned into sprints. So each project has one product backlog and some of the stories in this product backlog are planned into each sprint.
This all translates into the following very simple data model:
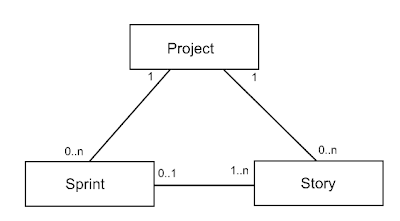
Let's see how we can translate this data model into GME.
Creating the project list in GME
The first step is to create a new project in GME. This will show you a nice empty application with just a pair of
gm:page tags.
<gm:page title="Scrum Project Manager" authenticate="true">
</gm:page>
Everything for our application will be inside the gm:page tags. If you want your application to have multiple pages, just add some more files to it. But for this application a single page will do.
Getting data into GME consists of two steps: defining the data itself and defining the GUI for it. The data itself takes the form of a
gm:list tag:
<gm:list id="Projects" data="${app}/Projects" template="projectList" />
The
gm:list tag defines a list of data that is used in the application. In many applications the data will be pulled from an external -RSS or Atom- feed. But we want to store the data inside the application, right in Google's mashup servers.
The data of our project list is stored under the
${app}. This is a location (a "feed" in GME terms) where the data of all users of the application is stored. If we don't want to share the data between users, we can store it under
${user}, which is data that is kept per user. Currently there is no way to have data shared between some users (but not all users of the application), although this feature will probably be added in the future.
To display the data in the list, the page needs a template. A template determines what fields to display and how to display them. It's easiest to use an HTML table, so we'll do that for now.
<gm:template id="projectList">
<table class="gm-table">
<thead><tr>
<td width="200">Name</td>
<td width="100">Product owner</td>
<td width="100">Scrum master</td>
<td width="45"> </td>
</tr></thead>
<tr repeat="true">
<td><gm:text ref="atom:title" hint="Project name"/></td>
<td><gm:text ref="gmd:productOwner"/></td>
<td><gm:text ref="gmd:scrumMaster"/></td>
<td><gm:editButtons/></td>
</tr>
<tfoot><tr>
<td colspan="4" align="right"><gm:create label="New project"/></td>
</tr></tfoot>
</table>
</gm:template>
As you can see we're mixing standard HTML tags, with GME specific tags like
gm:text,
gm:editButtons and
gm:create. Also notice the non-HTML
repeat attribute on the second
tr (a normal HTML table row). This tells GME to repeat that
tr for every item in the
${app}/Projects feed.
If we now compile and test this application, we get an empty table with a "New project" button. Pressing the button adds an empty row to the table, with fields to fill in the values for a product.

Note that editing and creation functionality are for free with GME. Although they're not very flexible, they allow you to quickly get started.
Creating the list of stories in GME
Next is a list of stories for a project. Since stories are always part of a project, we store the data under the feed of a project.
<h2>Stories for selected project</h2>
<gm:list id="Stories" data="${Projects}/Stories" template="storyList" />
This is where GME really adds a lot of logic automatically. The location refers to a child of the
${Projects}/StoriesProjects list we defined earlier. Each project in the
Projects list will have its own list of
Stories.
This list also needs a template to display it, which is really similar to the one for the projects.
<gm:template id="storyList">
<table class="gm-table">`
<thead><tr>
<td width="200">Title</td>
<td width="75">Type</td>
<td width="25">Estimate</td>
<td width="100">How to demo</td>
<td width="45"></td>
</tr></thead>
<tr repeat="true">
<td><gm:text ref="atom:title" hint="Story title"/></td>
<td>
<gm:select ref="gmd:storyType">
<gm:option value="user" selected="true">User</gm:option>
<gm:option value="tech">Tech</gm:option>
</gm:select>
</td>
<td><gm:number ref="gmd:estimate"/></td>
<td><gm:text ref="gmd:howToDemo"/></td>
<td><gm:editButtons/></td>
</tr>
<tfoot><tr>
<td colspan="5" align="right"><gm:create label="New story"></td>
</tr></tfoot>
</table>
</gm:template>
Now the only tricky bit we still need to do for the list of stories, is that it needs to be refreshed when the user selects a different project. This is quite easy, by setting an event handler.
<h2>Unplanned stories for selected project</h2>
<gm:list id="ProjectStories" data="${Projects}/Stories" template="storyList">
<gm:handleEvent src="Projects"/>
</gm:list>
This tells the story list to refresh itself when an event happens in the Projects list we defined before. So select a different project will display the stories for that project.
So after adding the story list and adding some projects and stories, our application looks like this:
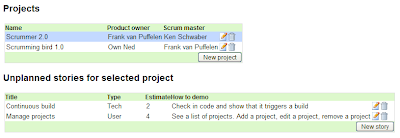
We can easily do the same for the list of sprints for the project. Since this is really similar to the list of stories, I won't show the code here. If you want to have a look at the code, look at the finished project on
http://scrummer.googlemashups.com.
Last is the list of stories for the selected sprint. Note that stories can either be part of the project or part of the sprint. So for now we'll call the first type "unplanned stories". Later we'll want to share the stories between the project and the sprints.
Since the list of stories is -again- really similar to the list of unplanned stories, we won't show the code here. But when we now run our mashup it looks like this:
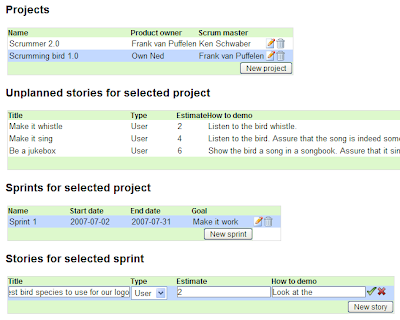
At the bottom you can see that I am entering a story. This is almost a usable application, at least for entering and browsing the data. To make it something you'd really want your entire team to use for your daily managing of Scrum projects, it would require more work.
That's it for now. If you want to have a look at the finished code or play with the application, go to
http://scrummer.googlemashups.com.

 DevX is a nice development site that sometimes has very interesting content. And one of the reasons their content is good is that they usually include quite a lot of screenshots and diagrams. This just makes their articles so much easier to follow. On screen the articles show the images at a reduced size. Which makes sense, because the images are often full screen screenshots which would otherwise leave hardly any room for text.
DevX is a nice development site that sometimes has very interesting content. And one of the reasons their content is good is that they usually include quite a lot of screenshots and diagrams. This just makes their articles so much easier to follow. On screen the articles show the images at a reduced size. Which makes sense, because the images are often full screen screenshots which would otherwise leave hardly any room for text.






















